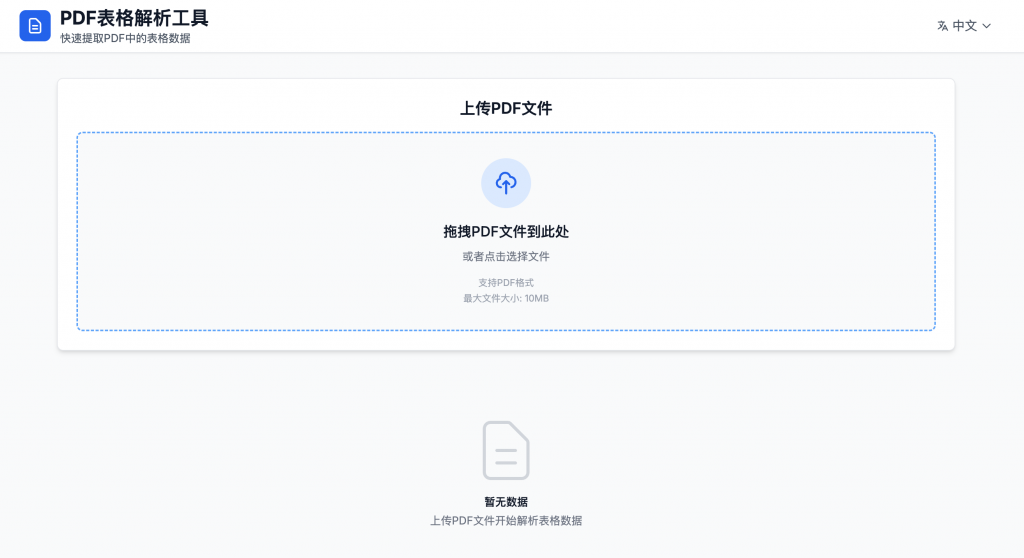
最近发现有朋友有解析PDF 发票的需求,所以上线了这个小工具来帮助他们:
一、功能
目前仅实现了基础的表格解析功能,而且暂时不支持图片类型的发票解析,所以需要进行特殊的内容解析的,可能需要和我联系定制
当前发票采用对PDF内部绘制数据进行代码分析,来实现完美的解析情况,但是并不是对所有PDF都能生效,需要验证,和调整参数,目前还没有实现调整参数的功能
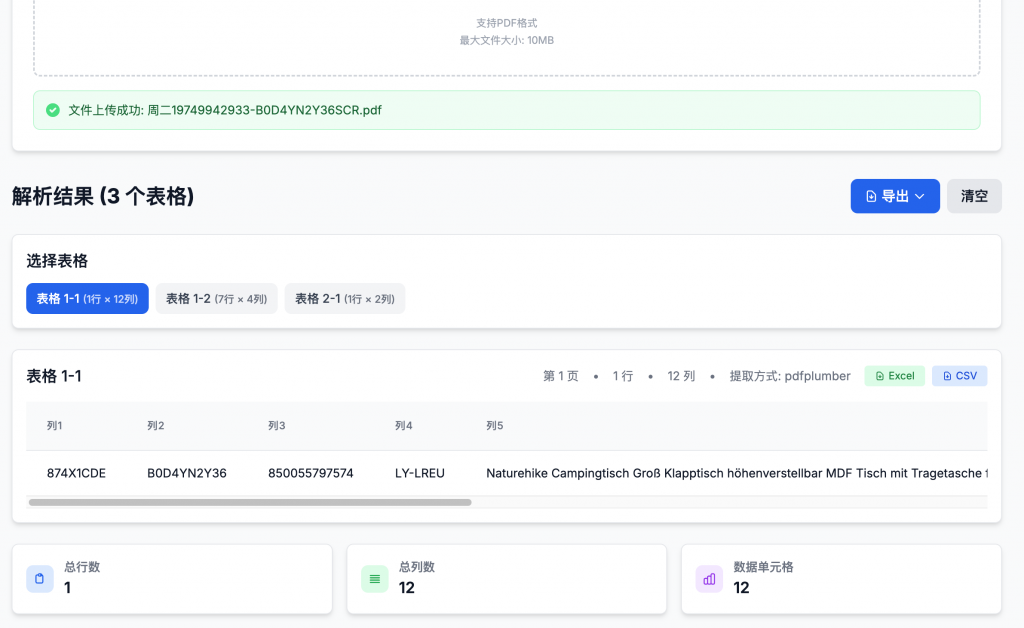
支持导出解析数据为 Excel 以及 CSV 文件,方便使用
二、后续计划
增加解析参数配置化,以适配api解析方案
后续我准备加入文本解析,并定制成API来提供服务
目前我考虑到一个更靠谱的方案,可以使用AI来做二次校验,所以利用AI来保证解析结果的正确性也在我的计划之内
网站地址:https://pdf.zklighting.ltd
了解 Hana - 探索有趣的世界 的更多信息
订阅后即可通过电子邮件收到最新文章。


暂无评论